In this article, we’ll look at 4 real-world patterns using Kafka and the trade-offs they come with.
These patterns are inspired by large-scale applications I’ve personally architected and contributed to.
We’ll cover:
- Mono-partition topics
- Partitioning for ordering (partition keys)
- Service-internal topics
- The outbox pattern
Introduction
Apache Kafka is an open-source distributed event streaming platform used for everything from async service communication to high-volume data pipelines.
It’s a popular choice for building scalable and reliable distributed systems—especially in microservice architectures.
The catch: Kafka gives you a lot of power, but you only get the outcomes you want if you’re explicit about the trade-offs.
1) Mono-partition topics
All messages produced to Kafka are stored in partitions. Partitions belong to a topic, and for all practical purposes, a topic is identified by its name.
So you can think of a topic as a logical grouping of partitions.
Ordering: partition-level (not topic-wide)
Kafka ensures message ordering at a partition level and does not provide topic-wide ordering.
So if you have a topic with 4 partitions, messages are consumed in the order of insertion within each partition.
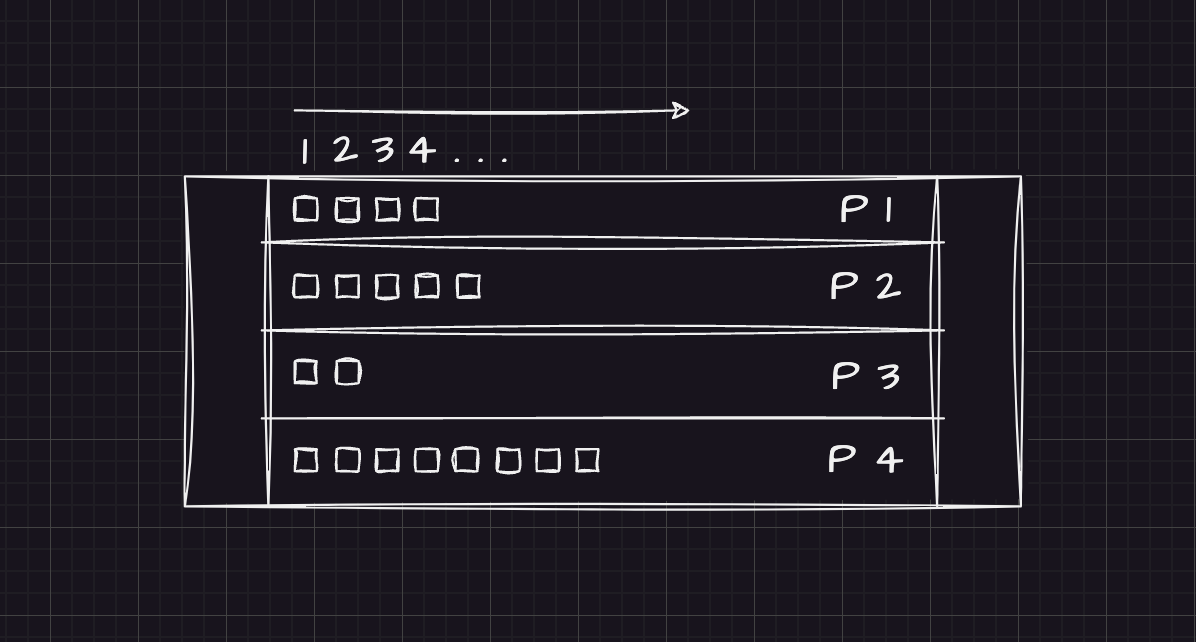
Topic with 4 partitions — ordering is per-partition, not topic-wide.
Kafka also enables horizontal scaling on the consumer side by increasing partitions: more partitions → more parallel consumption.
So the idea of a single-partition topic can feel unintuitive. But it’s useful in specific scenarios.
Example: an audit trail stream
Consider capturing a continuous stream of modifications in a database table.
If you want a comprehensive audit trail of all changes for a users table, a good approach is to publish events to a users_table_events topic with a single partition.
As records are inserted/updated/deleted, you publish a corresponding event in the exact sequence those changes occurred.
Pros
- Ordering guarantee: strict ordering because everything is in one partition.
- Simplified consumer logic: no partition coordination.
- Deterministic recovery: on failure, resume from last offset without cross-partition synchronization.
Cons
- Limited parallelism: a single partition can become a throughput bottleneck.
- Reduced fault tolerance (operationally): if that partition becomes unavailable, the topic is effectively unavailable.
- Performance constraints: consumer processing speed becomes the critical path; backlogs can build quickly.
2) Message ordering using partition keys
This is the most common pattern.
In Kafka, partition keys are used by the producer client library to decide which partition a message is sent to.
Common partitioning strategies
- Round-robin
- Key-based
- Hash-based
- Custom partitioner
Each strategy has trade-offs (deserves a post on its own).
By default, producers distribute messages round-robin.
If a key is set while producing a message, then messages with the same key are always sent to the same partition.
Kafka guarantees FIFO ordering for all messages that share a key (because they’re on the same partition).
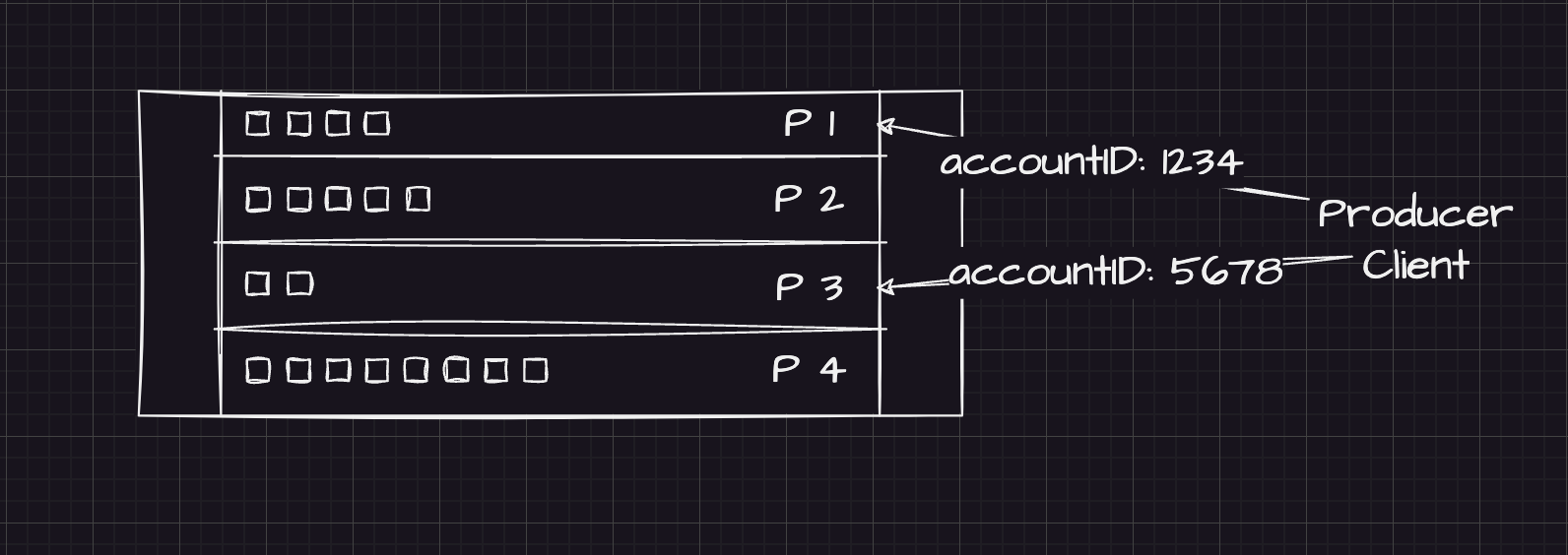
Key-based partitioning — FIFO ordering is guaranteed within a partition.
Example: accounting transactions
In domains like accounting or event sourcing, ordering isn’t optional.
If you use an accountId as the partition key, all transactions for that account are processed sequentially, preserving consistent balance computation.
Pros
- Message ordering (per key): related messages stay in the same partition.
- Parallel processing: different keys can be processed in parallel across partitions.
- Consumer affinity: enables efficient state management (same key → same consumer instance, depending on assignment).
Cons
- Data skew / hot partitions: some keys may dominate traffic.
- Partition count trade-offs: too few partitions limits scale; too many adds overhead.
- Key selection complexity: requires domain knowledge; poor keys produce imbalance.
3) Service-internal topics
This pattern is less common, but it’s used in real systems (including at Nubank) to handle time-consuming work within a service boundary.
Instead of publishing events for other services, you use a topic as a queueing mechanism to offload expensive computation while keeping request/response paths fast.
Example: scheduled database extraction
In Nubank’s data ingestion context, an extraction service needed to periodically extract data from 300+ microservices/databases in the transactional environment.
That extraction work is expensive.
Using a service-internal topic:
- the scheduler triggers the extraction service
- the service enqueues a batch of extraction tasks
- consumers scale horizontally to process those tasks
This allows the service to respond quickly to the scheduler while still handling large volumes of extraction work.
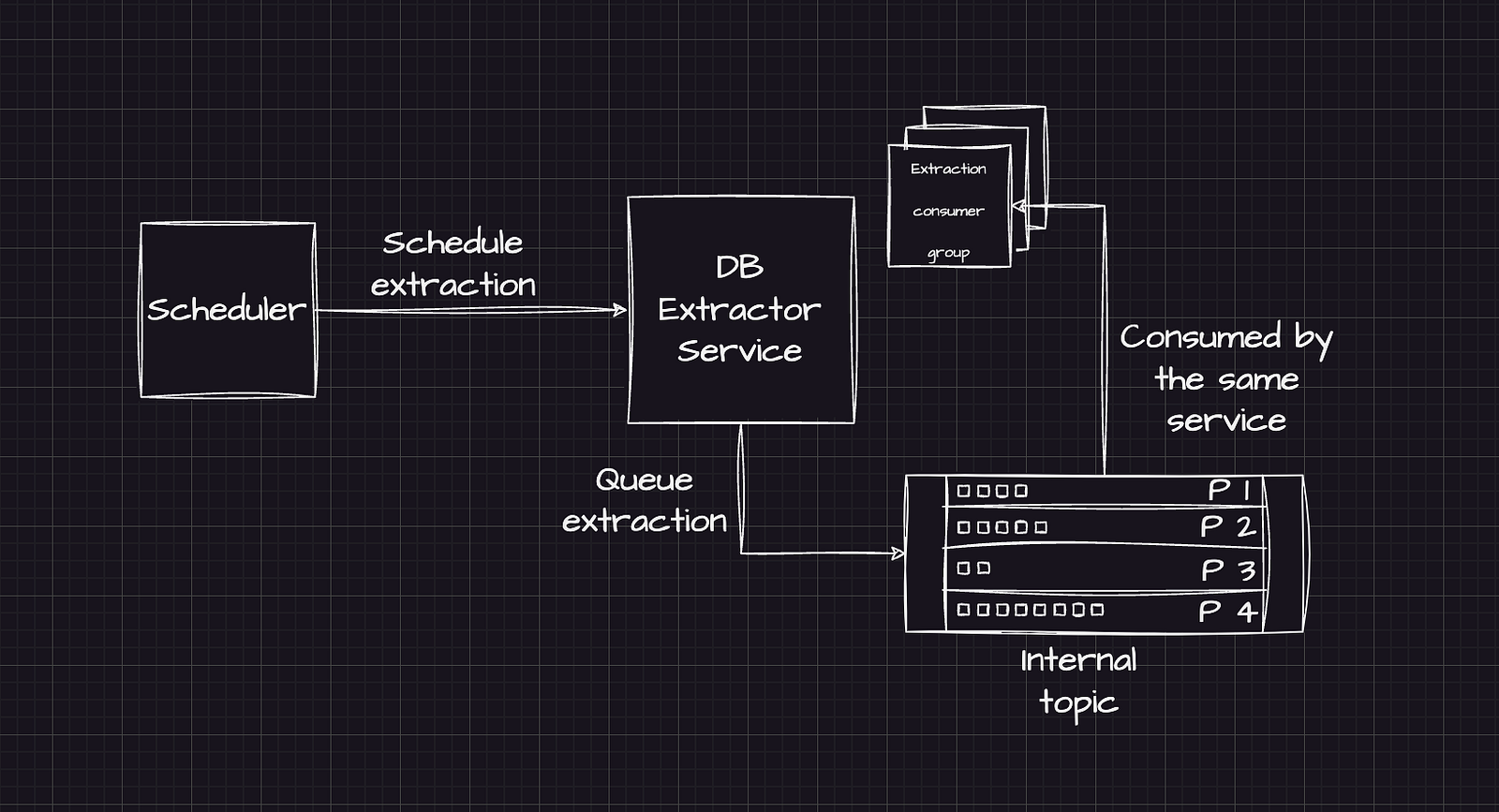
Service-internal topics — use Kafka as an internal queueing mechanism.
Pros
- Flexibility: internal topics evolve without coupling to other services.
- Fine-grained access control: restrict producers/consumers to a small surface.
- Performance optimization: tune topic configs (retention, compression, replication) for the internal workload.
Cons
- Increased complexity: more topics to manage; requires documentation and discipline.
4) The outbox pattern
The outbox pattern is used in microservice architectures to ensure reliable and consistent event-driven communication.
The core idea:
- each service maintains an outbox table in its own database
- instead of publishing directly to Kafka inside the request path, the service writes the event to the outbox as part of the same DB transaction as the state change
- a separate outbox processor publishes events to Kafka asynchronously
This avoids the pitfalls of 2PC (two-phase commit).
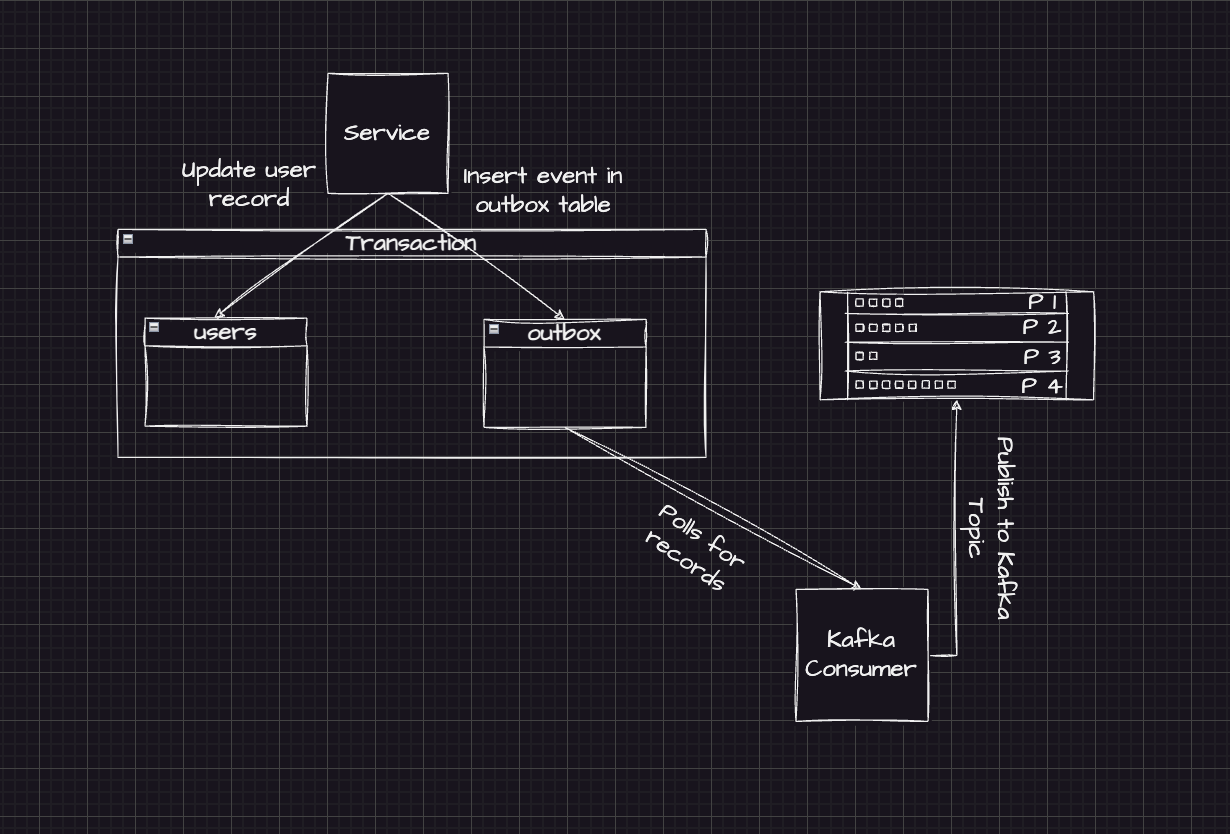
Outbox pattern — transactional write + async publish for reliable eventing.
Pros
- Data consistency: state change and outbox event are committed atomically.
- Fault tolerance: processor resumes from last successfully published event.
- Scalability: outbox processors can scale horizontally (with coordination trade-offs).
Cons
- Increased complexity: more moving parts (outbox table, processor, idempotency, retries).
- Latency: events are delayed by polling/processing cadence.
- Synchronization challenges: linking data changes to events correctly can be tricky in multi-step workflows.
Despite these challenges, the outbox pattern remains a strong approach for reliable event-driven systems.
Conclusion
Kafka is flexible—but it’s not magic.
Before picking a pattern, evaluate your constraints:
- required ordering
- throughput
- failure modes
- operational overhead
- team maturity and ability to debug async systems
The best Kafka design is the one that makes your system’s trade-offs explicit and operable.